


Abstract
We all live in a world where analyzing a massive set of unstructured data is becoming a business need. And the time we spend on the internet is basically the time we spend on social media. Even our daily life is affected by the people around us. And we are tending to change our opinions and thoughts towards something based on other people’s ideas and opinions. Some may call this bad and at the same time, some may call it good. Anyway, if we have the ability to think of other’s opinion that’d be really helpful and that’s when sentiment analyzes comes up. sentiment analysis we do classification of the data samples into positive, negative or neutral classes and bring out proper conclusions from the data.
we have done a meta-analysis of data obtained from 20 peer-reviewed scientific research studies (2009–2017) describing the Sentimental analysis using PSO and how PSO can help increase the productivity of twitter.
Key Words — sentiment, twitter, PSO, cluster, big data
Introduction
Swarm is a large number of agents interacting locally with themselves. In Swarm there’s no supervisor or central control to give orders of how to behave. Swarm-based algorithms are popular in this age hence its’s passion of nature-inspired, population-based algorithms that can produce high quality product with low cost and fast solutions to situations that are identified as complex and hard to solve [1][2]. Because of that reason Swarm intelligence is becoming a million-dollar gem in the category of Artificial Intelligence that is ready to collect the pattern, lifestyle and behavior of social swarms in the environment, for example, bird flocks, honey bees, ant colonies, and fish schooling. Even though these agents (These insects/ Swarm individuals) are simpleminded with not enough experience on their own, they all work together to achieve a common goal for their survival.



It’s not a matter of knowledge and the main mechanism of this interaction is called stigmergy which uses agents or actions for indirect coordination [3]. According to [3] Stigmergy is a well-defined form of self-organization. It produces a complex structure, seemingly intelligent structures, without the need for any control, planning or any direct communication in between the individual agents.
The PSO algorithms are most fascinating and pulled in to the researcher in the field of the fuzzy logic system, neural network, optimization, pattern recognition, robot technology, signal processing, etc[4].
To delete unnecessary duplicate attributes from a dataset we can use feature selection methods. Removing those attributes is a must because at the end of the day we do not want to decrease the accuracy of the algorithm which we use to predict something in the future [5].
Feature selecting is not an easy task because the size of the search space, Search space is proportionate increases with the features that are included in the data set [5]. The key principle of the feature selection is to improve the quality and performance of the predictor. Feature selection acts as a bridge for the preprocessing and we are defining the feature and selection process just before we step in to the extraction process.
Applications of Feature selection includes data classification, image classification, cluster analysis, data analysis, image retrieval, opinion mining, review analysis, etc. Using a method called wrapper method, feature extraction can be done using two stages: The stage one is, extracting all the Twitter data as a dataset and we transform this tweet into a normal text stage. What we do in the next stage is all about adding more features to the feature vector [1]. A class label is assigned to each tweet data in the training data sector and then pass these data to several classifiers for the process of classification and at the end, we get classified tweet data which are either positive, negative or neutral. Wrapper method achieves superior results than filter methods. FS is seen as an optimization problem because obtaining an optimal subset of relevant features from irrelevant and redundant data is very important. Many evolutionary algorithms have been used for optimizing the feature selection, which includes genetic algorithms and swarm algorithms. Some of the swarm-based optimization algorithms [7] for feature selection include Particle Swarm Optimization (PSO), Artificial Bee Colony (ABC) and Ant Colony Optimization (ACO).

In order to do the research scientific articles published on the IEEE related to sentiment analysis were collected and reviewed. All these articles used sentiment analysis on their research in many ways. Those previously work helped this research. Obtained knowledge about the technologies and tools they used for the sentiment analysis and how to obtain results within them. Previous publications have discussed on following matters.
[1] In this paper the researchers did several studies to investigate the use of Twitter to analyze ongoing health-related tweets and they outline that using Twitter data as a channel to reach out to the public to deliver more information about infection, diseases are a more efficient way in this age. English and Arabic tweets are collected from 3 different countries such as Dublin, London, and Boston. When searching and extracting for tweets they used more restricted queries to select the tweets among potentially identified healthcare ones that very likely to be relevant to healthcare. Then we used the narrow-identified tweets to train a support vector machine (SVM) with the linear kernel to classify the remaining identified tweets as relevant or irrelevant to healthcare. They’ve built three data sets a positive(SetP) and a negative(SetN) set for the training the models, and the set of potentially relevant tweets(SetT), which would be classified by the SVM classifier.
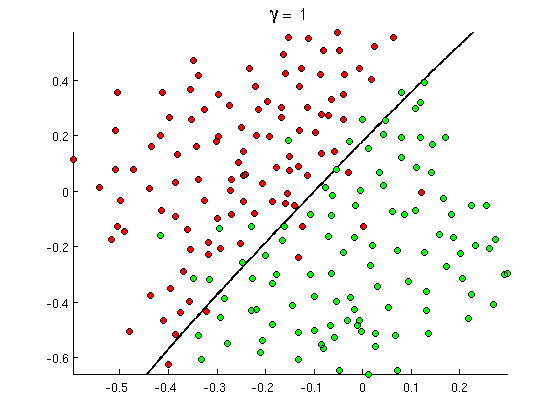
Extensive analysis is applied to the identified health-related tweets from each stream. For a fast and robust matching between tweets, we keep only the main content text of tweets by removing all hashtags, name mentions, URLs, punctuations, symbols, emoticons, and retweet symbols. As a result, they extracted the most popular tweet; most shared link or image related to healthcare then applied sentiment analysis to figure out public satisfaction about health (used sentiStrength tool to figure out sentiment), the top frequent words, terms, and hashtags related to healthcare and topics what people are more likely to discuss about (tweet about). The top frequent words, terms, and hashtags (excluding the stop words) are used to draw a tag cloud, where font size used for the different terms indicates their frequencies. The tag-clouds helps to summarize the most popular terms in the tweets, which in turn indicate the most popular topics people are interested in.
In this paper [2], They majorly target Stroke and Telemedicine; Stroke plays a major part when it comes to Death and disability. Thrombolysis and strokes can be easily treated if the patient is treated within 4.5 Hours. In this paper, they have got feedback from neurologists (Altogether 25 person) from Milan, Naples and Rome. Nearly 50% of the neurologists are worked in general infirmaries and the rest is divided in University Hospitals, Research Hospitals (IRCSS Foundations) and regional hospitals. An online questionnaire was held during the summer of 2017 to evaluate the type/quality of different hospitals, type of structure working, amount of thrombolysis-thrombectomy/ year, the ability of a network to estimate neuroimaging or to organize transfers of patients to other hospitals and finally to evaluate the type of technology that uses in telemedicine for patients or clinical needs. By the help of using Statistical Package for the Social Sciences SPSS software descriptive analysis with absolute and percentage frequencies of the qualitative variables was performed. According to the knowledgeable, in most scenarios (approximately more than 80%), there’s already an established network for treatment of Stroke. Inside that same network, hospital care was not identified as standardized and the network for the consultation of neuroimaging amongst hospitals was missing in 33.33% scenarios. Besides that, network consultations (via telephone or any other mean) were shown 62.5% possibility in the same network and also 43.86% of clinical cases were appeard to be evaluated using video/audio teleconference. Exactly 50% of physicians are showing the adoptability of using their own mobile phones with nonprofessional systems and social media (eg: WhatsApp®), Skype®, Facetime®, Telegram®) while only 25% of doctors use professional teleconference systems (Ciso®) and the rest use medical devices.

[3] In this paper the author has judged the likelihood of using several data sources for the prediction of EDvisits related to Asthma, Twitter to extract tweets related to asthma including asthma-related keywords, air quality data gathered from sensors, historical electronic health records indicating asthma-related visits to an emergency room and also search trends from Google within same time period in a same unique geographical area. Clinical collaboration from PCCI suggested several related keywords to use as a rod to catch public streaming tweets using Twitter API. From 11–10–2013 to 31–12–2013, they’ve been able to gather a dataset consist of 464 845 785 general tweets and 1 315 390 asthma-related tweets. On a regular basis, 15000 asthma related tweets are posting from all across the world in a day. Used ‘coordinates’ and ‘location’ fields to identify the geographical location of each tweet. But in most cases, it’s unable to collect the geographical location of the tweet, in such cases, they track down user’s profile location and extracted that location as the geographical location. First tweets are collected the pre-processed tweet with removing unnecessary content. Then engaged with a machine learning classification technique called artificial neural networks (ANN) to extract asthma-related tweets. In the training dataset each tweet contained at least one asthma-related keyword, and the dataset was divided in to three sections.
After that, they developed a prediction model to evaluate the frequency of Asthma ED visits using a combination of independent variables from the aforementioned data sources. Each Dataset was different by one another as they gathered from different data sources. The first step is to transform data into more compatible dataset by normalizing dataset using standard normalization technique (z-score), and then for the prediction model, used four distinctive classification methods Naive Bayes, Decision Trees, ANN, and SVM.
To minimize classification errors, the use of adaptive boosting technique and stacking technique has being used.
[4] According to the author, the scalability of good clustering technique is based upon the estimations of comparability. Clustering is an effective device of seeking and in this paper the author points out that using PSO algorithms to clustering twitter data stream is much more efficient than any other data clustering algorithms. Among many methods proposed for feature extraction, the PSO algorithms work more efficiently. These algorithms find the best solutions according to the knowledge obtained from previous iterations. The whole tweet data clustering method is labeled into four phases: a) Tweet data gathering b) preprocessing of gathered tweets c) Feature extraction and d) Data clustering using PSO. With the use of Twitter API, every 1000ms we developed our program to gather streaming tweets.
Then storing each tweet in a certain file according to its category, as the second phase, the data cleansing is done for cluster analysis and then comes the tokenization to divide each word in a tweet. Then as the last phase, PSO is applied to preprocesses tweets for clustering. The first step is to initialize the number of particles. Afterward of the initialization phase, assigning each tweet to its neighboring centroid vector for each particle is next, the health of each particle is generated by studying the average similarity between the cluster centroid and a tweet in the document vector space. In order to minimize the inter-cluster distances, we measured the distance path between the data vectors within the given cluster. To maximize the cluster distance, we have evaluated the distance between the centroids of the cluster. To the overall reports generated, we have undertaken almost 30 simulations and the proposed algorithm has taken 1000 functions to effectively evaluate the results.
[5] In this paper the author is giving the audience an important message which is the Alerts are going to be an essential art of near future remote health monitoring. For such capability, we must evaluate the practicability of leveraging online social media for such Aptitudes. In here, they have developed a medical notification trigger using facebook API to develop a facebook application. And there are four perspectives this system which is: The view of the patient, the doctor, the professional career, family member and finally the viewpoint of the carer network. The suitability of the application was analyzed as well as an initial examination of the reliability of alert delivery. We conclude that online social media platforms could offer suitable platforms for alerts in remote health monitoring.
[6] In this research paper, the authors try to determine the sentiments of the candidates of the Presidential election of USA, Donald Trump, Hillary Clinton, and Bernie Sanders were among the top election candidates. So here, what they did is extracted relevant, matching tweets for each candidate using keywords, hashtags, and mentions. 10000 labeled tweets are extracted for three candidates (Bernie Sanders, Donald Trump, and Hillary Clinton). What this system meant to do is extracting tweets and accomplishes political sentiment analysis on the gathered dataset. The process includes four stages: i. Retrieval stage, ii. Preprocessing stage, iii. Analysis stage, iv. Visualization stage Public tweets are extracted from Hillary, Trump, and Bernie using Twitter API using python, then all the tweets are preprocessed and filtered into meaningful sentences in the English language. Polarity and the subjectivity is calculated by a unique algorithm and the library NLTK used hence they’ve been working with human language using python framework. TextBlob in python was used to processing of textual data.
[7] In this paper the main goal is to reveal the views of the leaders of two big democratic parties in India, data was collected from the public accounts of Twitter. Opinion Lexicon was used to find a total number of positive, neutral and negative tweets. Findings show that analyzing the public views could help political parties transform their strategies. Extracted real time tweets using Twitter API for the comparison of two political parties. They used two sentiment analyzers named SentiWordNet and WordNet were used to determine the positivity or negativity of the relevant tweet. A negation handling and Word sequence disambiguation (WSD were used to add more accuracy to the model. And the confident of polarity calculation is done by using the library textBlob in python then to validate the results, SVM and Naïve Bais has been used. Tweets are extracted using Tweepy API with the help of standard search tool and gathered 100000 tweets based on around 20 hashtags in both English and Urdu languages. Then they determined the sentiment using 3 analyzers. To validate the results we obtained, converted the .csv files to. arff format then recorded the accuracy of each analyzer under each model.
[8] In this paper the authors have studied different aspects of medical sentiment in health-related texts that may relate to the following: Health status, Degree of medical condition that impacts patient life, Consequence of a treatment, Opinion towards a treatment, certainty of a diagnosis. For this work, we have collected a corpus consisting of 7,490 user blog posts from popular medical forum ‘patient.info’ which is split on the basis of two major medical sentiment aspects, namely ‘medical condition’ and ‘treatment’. The corpus is manually annotated with a predefined set of categories. Finally, a Convolutional Neural Network (CNN) based model is developed for medical sentiment classification. SentiWordNet lexicon is used for sentiment calculation for the analysis. They extracted posts fron medical blogs and observed that patient’s thoughts on a a symptom or medical condition is majorly based on his/her opinion. After deep analysis of data, they have observed that majority of the medical sentiment occurs in the vicinity of the term ‘feel’ and its variations. So, they used the word ‘feel’ as target word and observed that these words can provide an effective clue in capturing the sentiment.
[9] In this paper, real time clustering is done by using static and dynamic algorithms using Hadoop network. They’ve used a combination of PSO and K-Means algorithms which they called as KSPSO. As usual Twitter’s Rest API is used to collect tweets and then the pre-processing with tokenization is being made. Porter Stemmer Algorithm is used to remove stop words in the data set. Document matrix is advised to be prepared after data preprocessing. By testing with various particles, they applied PSO algorithm and discussed about Fitness, Precision and Recall in a cluster.
[10] In this paper; the authors describe about Swarm in detail and how we can use Swarm methodologies such as Particle Swarm Optimization to do a proper feature selection in a cluster analysis. Rapid PSO is identified as an advanced version of PSO. Used various number of python libraries such as NumPy, SciPy, Pandas, Matplotlib for data analysis process.
Using Rapid Particle Swarm Optimization for feature selection have shown incredibly accurate results with measurable levels of Precision and Recall. And also, less amount of time than standard PSO.
The rest of this chapter is structured in the following order. Section II is a description of materials and methods. Section III explains the results of the research. We discuss our findings with relevant literature and summarize our comments and some of the implications of our findings in Sections IV and V.
Material and Methods
Based on Swarm Intelligence a simple mathematical model was developed by Kennedy and Eberhart in 1995 [8], they majorly want to describe and discuss about the social behavior of fish and birds and it was called the Particle Swarm Optimization (PSO). PSO is one of the most famous and very useful metaheuristics in the current age hence it showed the success of various optimization problems after applied on. The basic principle of this model is self-organization that describes the dynamics of complex systems. PSO uses an extremely streamlined model of social conduct to take care of the optimization problems, in a cooperative and intelligent framework.
In twitter, a user is permitted to write their own opinion and views in a short message on the social platform twitter [1] are termed as tweets. Tweets may contain characters, links, media or a recording. These tweets are not written to a standard and it has mostly short structures, slangs, abbreviations, mistakes in grammar, half-written sentences, misspellings and so forth. So, it is perplexing to expel the useful data from tweets because of their unstructured style. By applying to cluster we’re trying to reduce the complexity of finding the occasion or theme of the tweet composed. To extract specific words that are matching to a particular event data is addressed by vector space demonstrate using term recurrence and inverse term recurrence. So, Particle swarm change framework is the best method to handle this issue [5].
The tweet clustering process is consisting of below 4 modules:
1. Collection of Files
2. File pre-processing
3. File clustering with PSO
4. File Post-processing.
1. File Collection
We collect individual tweets related to Telemedicine, Heart Strokes and Epilepsy data and then store each in a separate .csv file. So, at the end of execution of our python code. We were able to collect more than 30000 data for each file based on around 10 keywords for each category (each file):
File 1 — Telemedicine.csv (Telemedicine + Digital Health tweets)
Ø hashtags Used: #telemedicine #telehealth #digitalhealth #ehealth #digitalpatient #digitaltransformation #telemedicinetoday #ehealthissues
File2 — Epilepsy.csv
Ø Hashtags used: Epilepsy #epilepsyawareness #epilepsyaction #epilepsyalerts #epilepsybed #epilepsycongres #epilepsysurgery #epilepsysurgery #Epilepsytreatment #seizures #seizurefree
File3 — HeartStrokes.csv
Ø Hashtags used: #HeartDisease OR #stroke OR #Stroking OR #strokepatient OR #StrokeSurvivor OR #hearthealth OR #Stroke OR #HeartFailure’
We gathered these tweets from the date 22nd Sepetember 2018 to 01st of October 2018 and Extracted 14 (main) data fields from one tweet hence we need more specific data related to one tweet. Here are the data fields that we were able to scrap:
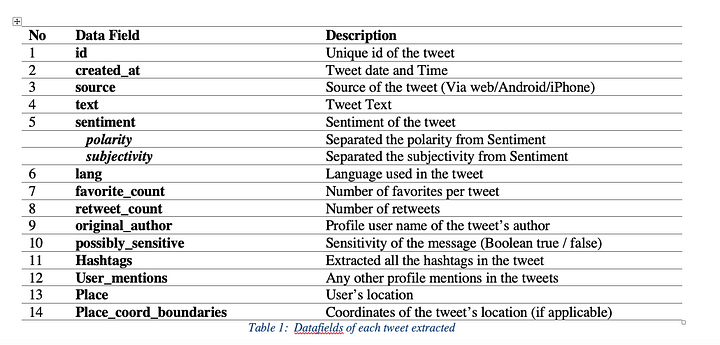
2. File Preprocessing
Tweet text must be tokenizing before calculating the sentiment value so first of all, the library preprocessor in python was used to do the basic clean operations on tweets:
a) Clean the tweet by removing unnecessary long words of the text (eg: Word ‘soooooo’ instead of ‘so’).
b) Links, images and such keywords like “RT” as for retweets are ignored.
c) Remove mentions and punctuations.
d) Emoticons and hashtags should be removed.
e) Emojis (Symbols, Emoticons, Flags and other emojis in Smartphones) should be removed.
f) Stop words, Frequent words and rare words are removed because that’s identified as noise in the data.
After all that preprocessing all that remained was nearly 25000 data of each file.
3. File Clustering using adaptive PSO
Then, I’ll do some data analysis to figure out how frequent users tweet about those 3 categories, and how do they manipulate hashtags and how the data distribution among 3 categories are.
After preprocessing of dataset, then we go to the next stage which is clustering using adaptive PSO.
Results
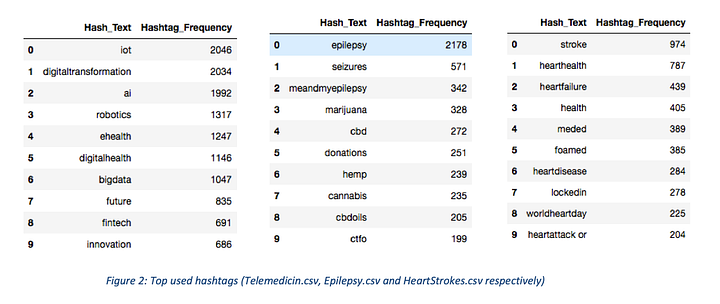
Here are the top used hashtags in the files Telemedicine.csv, Epilepsy.csv and HeartStrokes.csv respectively.
Pie Chart — Telemedicine.Csv
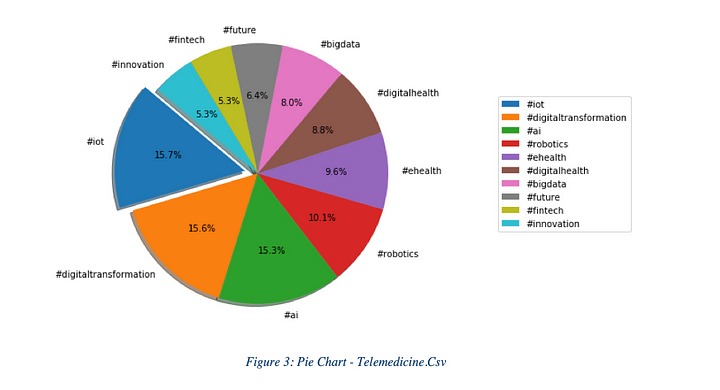
Figure 3: indicate that 15.7% of the tweets include the hashtag #iot and stand at the top of the list. As second and third, #digitaltransformatin and #ai standing respectively.
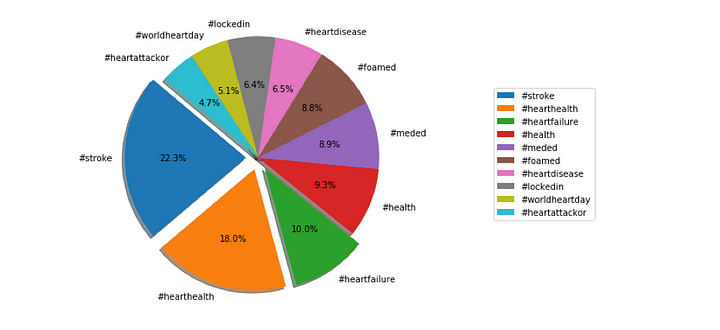
As shown in figure3, #stroke — 22.3%, #hearthealth — 18.0% and #heartfailure- 10% standing as most used hashtags related to heart stroke tweets.

Figure 5: Hashtag distribution of Epilepsy data
In epilepsy data, most people used the straight word #epilepsy with their tweets, to be exact it’s 45.2% of 25,000 tweets.
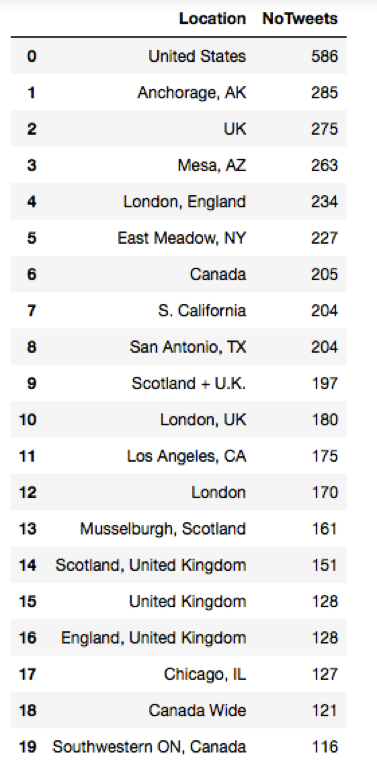
Most tweet profiles are from the US, we only tracked the location of the tweet’s user hence most people would not like to share their location info as their privacy concerns.
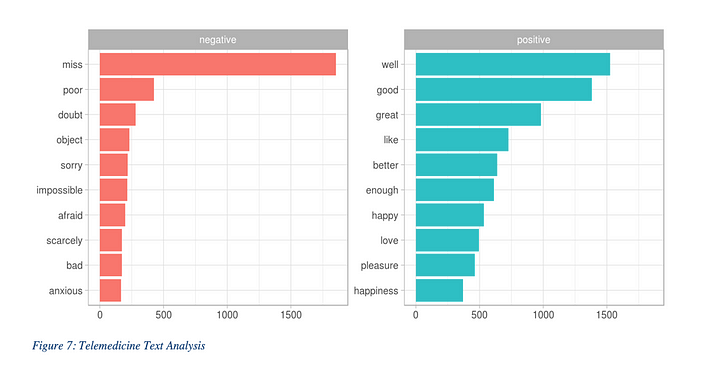
And I wanted to get an idea about what people think about Telemedicine hence It’s still on its way to success and public opinion should vary:
Discussion
The aim of this study is to get more understanding about how telemedicine is discussed in social media like Twitter and the people’s opinion towards that. And also, we’ll be able to come to a final decision about people’s attitude towards Heart stroke-related diseases, and critical situations like Epilepsy and also towards Telemedicine.
Before coming to our discussion, Let’s see some points on previous researches; Here in this research paper [1], Analyzing Real-time tweets can led to decide much more efficient decisions for future benefits, in this case, the top frequent tweet is about public awareness and the next popular tweet is all about 135000 health care professionals applied for 1760 jobs in Dublin, Ireland, we can declare that its important in hiring more employees in the healthcare sector. The third is very important to professionals in healthcare sectors, government, and probably insurance companies to be aware of the concern of such a big difference in price for the same procedure in two hospitals. When it comes to Telemedicine, some issues are raised in so many ways like in here [2], The key issue of this research is the lack of involvement of stroke experts, but on the other hand the coverage of urban areas and variety of hospital types came quite handy for the topic. When it comes to telemedicine the incorporation with the national guidelines stroke care pathway and proper standard care is a straightaway need. Telemedicine proves that it’s usage is a must and also huge but still, it’s going on with mostly nonprofessional devices or non-medical devices. As a conclusion, this paper suggests that there should be satisfactory access to Telemedicine equipment, so it will optimize the work of physicians in an enormous way. At last, they point out that the distribution of telemedicine in all across European countries is an urgent need.
PSO algorithm has resulted in good convergence of parameter value selection and yields the expected results optimally. Because of that, we have proposed the PSO algorithm to ensure that the compactness of the cluster must be intact and find the clusters which have larger separation in the cluster centroids. The result has shown that the proposed algorithm is given the gradual improvement when the cluster has larger separations and the distance between the centroids has also been witnessed that it has improved with preciseness.
[3] The proposed work here investigated the PSO algorithm on Twitter data streams to effectively cluster the data sets and tested that it has yielded better convergence with lower quantization errors. In general, it has given the good convergence based on the two simpler principles that it has taken the larger inter-cluster distance for the Twitter streams and smaller intra-cluster distance for centroids in the Twitter data streams. As the Twitter data stream is very large in size, the proposed PSO algorithm has followed the global search mechanism to find the optimum results of the clustering. We have compared the proposed algorithm with other existing algorithms and found that this proposed work has given the optimum results with lesser time by taking less parameter for clustering.
Analysis of the review article confirmed a significant gap in some of the published articles [5], [6] and [10]. For the analysis, they hadn’t taken enough number of tweets. [9], [11], [12] they have taken enough number of tweets for their research. Accurate results cannot be obtained with a smaller number of data. The disadvantage of this method is that in the case of spelling tweets, the presence of positive and negative words may not produce appropriate results, because the placement of positive and negative words in the sentence gives different conclusions. [7] they have used 27 million tweets. That is a good dataset for the analyze but they have to be careful with SVM because it has a limitation in speed and size on both training and testing data. In this research 120000 tweets were used for the analysis which is a considerable amount comparing with the other researches. It will assist to maximize the accuracy of the results of the research.
Evident from the outcome of this study, most of the users who talk about Telemedicine and Heart Diseases are located in the USA and the variety of hashtags are different inside a topic based on the Twitter user’s profile age also. Most important thing is that we should obtain a big data set for our analyze.
Conclusion
In this research we provide an effective way to detect and get an idea about how the public is thinking of the critical heart diseases and all the Telemedicine techniques, good and bad sides of those; Determining the positive and negative thoughts towards Telemedicine because some regional areas in the US are tweeting as requests for Telemedicine service for their rural areas. The government should be more aware of these regions and start making plans on spreading their telemedicine services as soon as possible. I was going to plot the location coordinates in a world map but I wasn’t able to do that so I must say that In future a plotting in a world map, especially those areas that are requesting more telemedicine services can be considered as a future research and what I discovered in this paper should also be helpful for researches observing Telemedicine issues.







{kind=link}
0 Comments